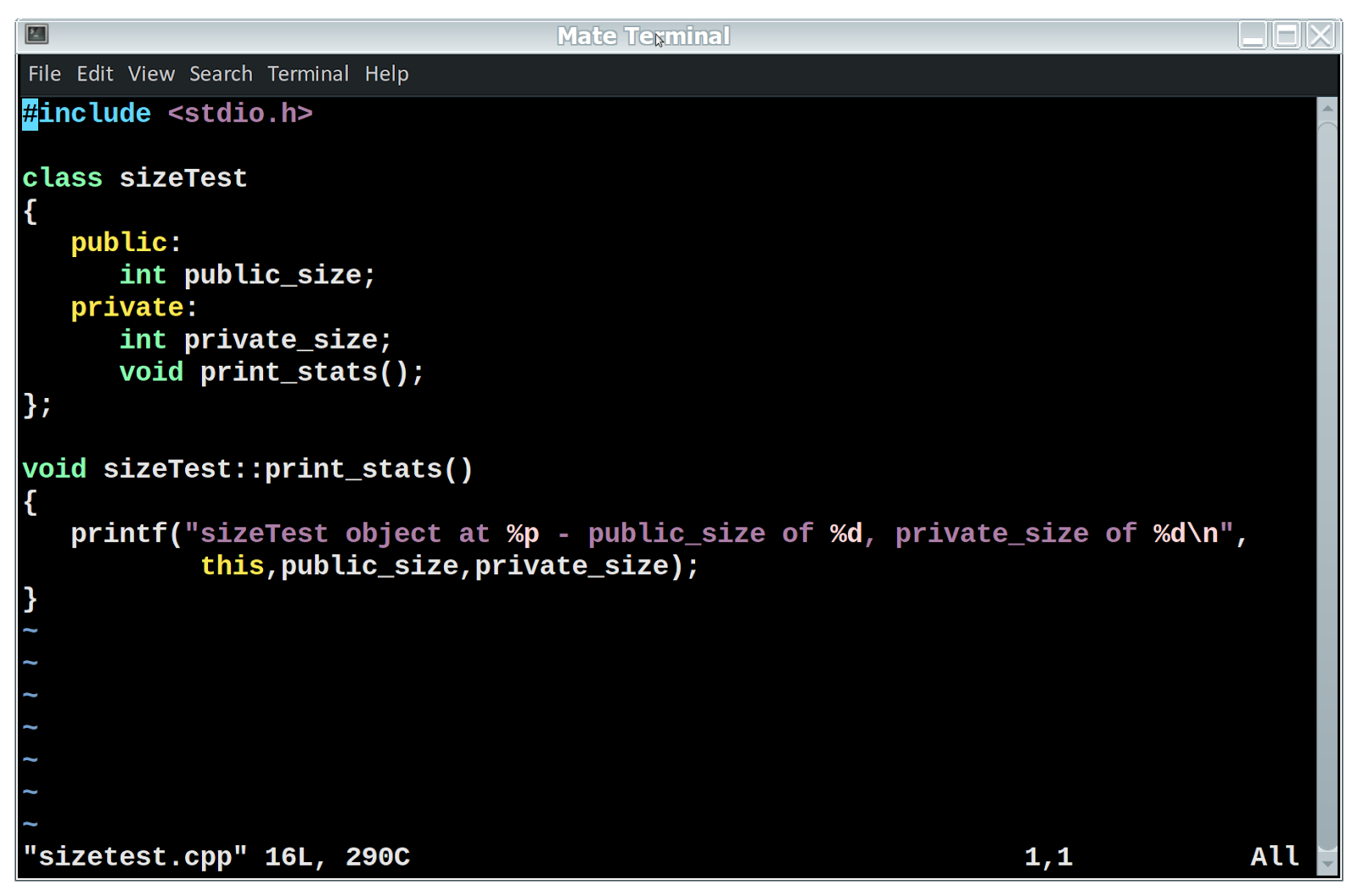
In todays world, one of the common things is to be able to serve SOAP requests. As an enterprise grows, the need for fast response times and optimizations at every possible place becomes more and more important. I wrote a generalized SOAP server in C++ using QT Creator and gsoap that connects to a database and runs in multiple threads with prepared statements. Its a little involved of a process, but I hope the ideas here can help others with similar problems.
Environment: QT Creator, Postgres 9.4, gsoap 2.8 on Ubuntu. Very little if any is OS specific, other than that its made for *nix. So, FreeBSD and the like should work just fine too.
By the end of this, you will have a SOAP server that connects to a database, that uses multiple threads which are already started and connected to the database, prepared cursors, and an easy path forward to develop new services on it. We will also add the ability to retrieve the WSDL from the service by accessing it via http://service/?wsdl . Otherwise known as a GET handler.
Step 1: Create the project in QT
In QT Creator, create a new project, QT Console application. For this example, we will use gsoap to create C++ classes which are generated from a .h file. It should place the generated files in a subdirectory named soap. First off lets create the soap definition file. In this example, soapDef.h, which will be running in the "beer" namespace and named "beersoap". Yup, its for a brewing website backend. Make sure you have network, core, and sql included and add LIBS += -lgsoap++
//gsoap beer service name: beersoap
//gsoap beer service port: http://localhost:7575/
//gsoap beer service namespace: urn:beersoap
/**
* Simple ping operation to verify operation
*/
int beer__ping(void *,char *&pong);
/**
* Count user records, used mainly for testing DB connection
*/
int beer__usercount(void *_,int &numUsers);
Secondly, to support WSDL retrieval, we can convert the wsdl file generated by gsoap into a C++ file with the text as a variable which we can reference by an extern. A little shell script magic will do that for us with the following file: wsdl2cpp.sh
#!/bin/sh
wsdlfile=${1}
cppfile=${2}
echo "const char *wsdlTxt = " > ${cppfile}
cat ${wsdlfile} | sed -e 's:":\\":g' \
-e 's:^:":' \
-e 's:$:\\n":' >> ${cppfile}
echo ";" >> ${cppfile}
And finally tie it all together inside your .pro file
GSOAPFLAGS=-S -L -c++11 -x -i -d $${_PRO_FILE_PWD_}/soap
gsoap.depends = $${_PRO_FILE_PWD_}/soapDef.h
gsoap.target = $${_PRO_FILE_PWD_}/soap/soapC.cpp
gsoap.commands = \
soapcpp2 $${GSOAPFLAGS} $${_PRO_FILE_PWD_}/soapDef.h && \
$${_PRO_FILE_PWD_}/wsdl2cpp.sh \
$${_PRO_FILE_PWD_}/soap/beersoap.wsdl \
$${_PRO_FILE_PWD_}/wsdl.cpp
QMAKE_EXTRA_TARGETS += gsoap
PRE_TARGETDEPS += $${_PRO_FILE_PWD_}/soap/soapC.cpp
Now, when we build, including the file wsdl.cpp will create a const char * named wsdlTxt that has the entire WSDL file in it. In our case with the GSOAPFLAGS we say server side code only, no library generation, use c++11, no xml files, create a C++ class for our methods, and the output directory is source/soap.
Step 2: Create Database
The next step is to create a database to test this out with. Create a users table, we are just going to have a method to count the records in there. And another table called prepstmts. Two fields, a char(32) or similar and a text fields. Once it connects, we will use it to create a collection of prepared statements. By far the longest running database operation is connecting and preparing a statement. We want to offload that to start up routines instead of during processing. Next, create a configuration file for the program to use. We will specify the location using QT's command line option parser framework.
# Beersoap config file
dbhost = localhost
dbuser = beergineer
dbpass =
dbname = beergineer
tcplisten = 7575
threadpool = 5
Ok.. now we have a config file, our makefile will handle the gsoap stuff for us automatically (remember to include all the .cpp and .h files it creates into your project, including wsdl.cpp), now lets do some coding and show how easy QT makes a lot of the mundane C++ tasks, and how relatively simple something as advanced as a thread pool can be written and managed.
Step 3: main.cpp
This is the application entry point. As any good programmer will tell you, your main function should do initialization, basic sanity checks, then launch the real application. QT makes things like parsing command line options in a nice, standard Unix like way really easy, especially with C++11. Here is my main.cpp file:
#include <QCoreApplication>
#include <iostream>
#include <QCommandLineParser>
#include "Config.h"
#include "Server.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
QCoreApplication::setApplicationName("beersoapd");
QCoreApplication::setApplicationVersion("DEV");
QCommandLineParser parser;
parser.setApplicationDescription("Beergineer Soap Server");
parser.addHelpOption();
parser.addVersionOption();
parser.addOptions({
{{"c","configFile"},"Config File Location","configFile"}
});
parser.process(a);
Config *myConfig = new Config(parser.value(configFile));
if (!myConfig->isValid()) {
std::cerr << "Config invalid" << std::endl;
return 1;
}
new Server(&a,myConfig);
return a.exec();
}
Dont worry about the Config and Server objects yet, we will create those in a minute. What this does, is calling it with a -h option shows the help, -v shows the version, and the config file we created earlier can be specified with either -c or --configFile. The output is formatted well and all the nastiness of getopt and the old school way is handled for you. The reason for a config file instead of a plethora of switches is extensibility, keeping commands reasonable in length, and for security. If you have everything as an option, any user on the machine can see things like passwords, etc.. if they are specified on the command line. The Config object is really simple and just reads a file, splits any lines that arent blank or start with # by the equals sign and stores it in a QMap, then provides an accessor method to get the values of it. Heres the header
Config.h:
#ifndef CONFIG_H
#define CONFIG_H
#include <QString>
#include <QMap>
class Config
{
public:
Config(QString confFile);
QString getSetting(QString name);
bool isValid() { return myValid; }
private:
QMap config;
bool myValid;
};
#endif // CONFIG_H
And Config.cpp
#include "Config.h"
#include <QFile>
#include <iostream>
Config::Config(QString confFile)
{
config.clear();
myValid = false;
QFile f(confFile);
if (!f.exists()) {
std::cerr << "File does not exist: " << confFile.toStdString() << std::endl;
return;
}
f.open(QIODevice::ReadOnly);
while (!f.atEnd())
{
QString line = f.readLine();
if (line.trimmed().length() == 0 || line.startsWith("#")) continue;
int idx = line.indexOf("=");
QString key = line.left(idx-1).trimmed();
QString val = line.right(line.length()-idx-1).trimmed();
config[key] = val;
}
f.close();
QStringList reqattribs;
reqattribs << "dbhost" << "dbuser" << "dbpass" << "dbname" << "tcplisten" << "threadpool";
if (!config.size()) return;
for (int i =0; i < reqattribs.size(); i++)
{
if (config.find(reqattribs.at(i)) == config.end()) {
std::cerr << "Missing required value: " << reqattribs.at(i).toStdString() << std::endl;
return;
}
}
myValid = true;
}
QString Config::getSetting(QString name)
{
if (config.find(name) == config.end()) return "";
return config[name];
}
As you can see, fairly simple, boiler plate code. Next we get into the actual networking part of it. Qt makes this exceptionally easy using the QTcpServer class. So without further adue, here is the Server.h class definition
#ifndef SERVER_H
#define SERVER_H
#include <QTcpServer>
#include <QVector>
#include "Config.h"
#include "SoapThread.h"
class Server : public QTcpServer
{
Q_OBJECT
public:
Server(QObject *parent,Config *confPtr);
private:
Config *myConfig;
void incomingConnection(qintptr handle);
QVector<SoapThread *> myThreads;
signals:
void newConnection();
};
#endif // SERVER_H
A few items of note here. Using this class is very easy, you pretty much just tell it which port / address to use and the override of incomingConnection will pass in the new socket descriptor. The vector of SoapThread objects are all initialized on start up and in the next file I will show how we connect a connection to a thread. Here is the Server.cpp file:
#include "Server.h"
#include <iostream>
#include "SoapThread.h"
Server::Server(QObject *parent,Config *confPtr)
{
setParent(parent);
listen(QHostAddress::Any,confPtr->getSetting("tcplisten").toUShort());
myConfig = confPtr;
int maxThreads = confPtr->getSetting("threadpool").toInt();
for (int i =0; i < maxThreads; i++)
{
SoapThread *p = new SoapThread(confPtr);
myThreads.append(p);
p->start();
p->moveToThread(p);
connect(this,SIGNAL(newConnection()),p,SLOT(serveRequest()));
}
}
void Server::incomingConnection(qintptr handle)
{
int maxThreads = myConfig->getSetting("threadpool").toInt();
int tries = 50000;
while (tries)
{
for (int i =0; i < maxThreads; i++)
{
SoapThread *p = myThreads[i];
if (!p->isBusy())
{
p->setPendingDescriptor(handle);
emit(newConnection());
return;
}
}
tries--;
sched_yield();
}
::close(handle);
}
Theres a lot packed in here, this is the heart of the application that does the magic. First in the constructor, we set up the listening socket, which returns immediately, the actual listening happens when the QCoreApplication enters its event loop in the exec() call. Then we create the threads, each one is created, then started, then, very important because its not intuitive, move the object to itself. What happens is the event loop and signal / slot dispatchers will remain in the current thread until you actually move it after the thread is started. The single signal is connected to each thread. The thread that has the socket descriptor set will process the request. In real practice a minimal number of threads will be started and if all of them are busy, another one will be started then used to serve the request, then as they are used less and less and there is a sufficient timeout, the thread will clean itself up. For this purposes though, this is just an example.
Now for the thread class itself.
#ifndef SOAPTHREAD_H
#define SOAPTHREAD_H
#include "Config.h"
#include <QThread>
#include <QReadWriteLock>
#include <QSqlDatabase>
#include <QSqlQuery>
#include "soap/soapbeersoapService.h"
class SoapThread : public QThread
{
Q_OBJECT
public:
SoapThread(Config *cfgPtr);
void run();
bool isBusy();
void setPendingDescriptor(qintptr);
QSqlDatabase dbHandle;
QMap<QString,QSqlQuery> prepStmts;
public slots:
void serveRequest();
private:
Config *myConfig;
beersoapService *mySoap;
bool myBusy;
QReadWriteLock myLock;
qintptr myPendingDescriptor;
};
#endif // SOAPTHREAD_H
A little bit to explain here. First, the code is in a threaded enivronment, so a lock is essential. Qt makes locking easy, but it must still be done with care. We also have not only a database handle, which must be unique per thread, but all the values in the prepstmts table (from step 2) will become prepared statements, stored by name in the prepStmts table.
And the implementation:
#include "SoapThread.h"
#include <QObject>
#include <QWriteLocker>
#include <QReadLocker>
#include "Server.h"
int get_handler(struct soap *s);
SoapThread::SoapThread(Config *cfgPtr)
{
myConfig = cfgPtr;
myBusy = true;
myPendingDescriptor = 0;
}
void SoapThread::run()
{
QWriteLocker lock(&myLock);
mySoap = new beersoapService();
mySoap->user = (void *)this;
mySoap->fget = get_handler;
dbHandle = QSqlDatabase::addDatabase("QPSQL",
QString("%1").arg((quintptr)this,QT_POINTER_SIZE *2,16,QChar('0')));
dbHandle.setDatabaseName(myConfig->getSetting("dbname"));
dbHandle.setUserName(myConfig->getSetting("dbuser"));
QString hostname = myConfig->getSetting("dbhost");
if (hostname.length() > 0 && hostname != "localhost")
dbHandle.setHostName(hostname);
dbHandle.open();
QSqlQuery pstmtq(dbHandle);
pstmtq.exec("SELECT * FROM prepstmts");
prepStmts.clear();
while (pstmtq.next())
{
QSqlQuery p(dbHandle);
p.prepare(pstmtq.value(1).toString().trimmed());
prepStmts.insert(pstmtq.value(0).toString().trimmed(),p);
}
pstmtq.finish();
myBusy = false;
lock.unlock();
exec();
}
void SoapThread::serveRequest()
{
if (!myPendingDescriptor || myBusy) return;
QWriteLocker lock(&myLock);
myBusy = true;
mySoap->socket = myPendingDescriptor;
myPendingDescriptor = 0;
lock.unlock();
mySoap->serve();
myBusy = false;
}
bool SoapThread::isBusy()
{
QReadLocker lock(&myLock);
return myBusy;
}
void SoapThread::setPendingDescriptor(qintptr d)
{
if (myBusy || myPendingDescriptor) return;
QWriteLocker lock(&myLock);
myPendingDescriptor = d;
}
Ok, to begin with, the real magic doesnt happen in the constructor. At that point we are still running in the original thread, however, once start is called in the top object, run() is called here, but in a new thread that this object represents. In there is where we make the connection to the database, create the prepared statements. and set up everything. The setPendingDescriptor method sets the descriptor of the incoming request for this thread to execute momentarily. isBusy returns if it is still executing a request. All variables read or set from outside the thread need the locking around them, as shown above. There is also way more error checking / handing that must be done for the database access / prep statements but for the sake of brevity I just connected. When the Server object has an incoming connection, the serveRequest function actually gets called in every thread. But since only the first non-busy thread got it set, the other ones just return immediately. Also in the run method, the gsoap object is created here and the fget field is set to a static function shown next. This supports non SOAP calls to the server (remember http://address?wsdl). Yup thats coming up. We also use the user field to point to the thread object so we have access to the public properties of the prepared statements and connected database handle.
The next and last file is the implementation of the soap methods themselves.
/*
* Core and standard functions for the beersoap service
*/
#include "soap/beersoap.nsmap"
#include <QString>
#include <QVariant>
#include "soap/soapbeersoapService.h"
#include "SoapThread.h"
extern const char *wsdlTxt;
/**
* \brief Used to determine soap service operation, simply returns the string "PONG!"
*
* \param [in] pong Pointer to return string
* \return status of soap operation in this case always OK
*/
static const char *pongStr = "PONG!";
int beersoapService::ping(void *_param_1, char *&pong)
{
(void)_param_1;
pong = (char *)pongStr;
return SOAP_OK;
}
/**
* \brief Handle GET requests
*/
int get_handler(struct soap *s)
{
if (!s) return SOAP_GET_METHOD;
QString url = s->path;
int idx = url.indexOf("?");
if (idx == -1) {
// handle generic get request here
return 404;
}
QString queryStr = url.right(url.length()-idx-1);
// WSDL Request
if (queryStr == "wsdl")
{
s->http_content = "text/xml";
soap_response(s,SOAP_FILE);
soap_send_raw(s,wsdlTxt,strlen(wsdlTxt));
soap_end_send(s);
return SOAP_OK;
}
return 404;
}
/**
* \brief Count the rows in the users table, demonstrates database access
*/
int beersoapService::usercount(void *_, int &numUsers)
{
(void)_; // unused
numUsers = -1;
SoapThread *sThread = (SoapThread *)user;
QSqlQuery q = sThread->prepStmts.find("countUsers").value();
q.exec();
q.isValid();
q.isSelect();
q.first();
numUsers = q.value(0).toInt();
q.finish();
return SOAP_OK;
}
So, after all of that, once you get it to compile and run, you now have gsoap objects running in a multithreaded server. The database objects are already connected and ready to go before running a service function, so as you can see with only a few modifications can be made to run very quickly. Hopefully some of the explanations and code here can help someone